
User talk:Profes.I.
Add topicMiscellanea
[edit]Hello, Profes.I. May I ask how you know Palaestrator? A new account being pinged by him to give agreement and being rather similar to his own account is normally something that arouses suspicion. —Μετάknowledgediscuss/deeds 18:04, 28 November 2017 (UTC)
- @Metaknowledge His contributing here is way older, he had contributed for months (if not longer) under various IPs until he followed my recommendation to create an account (I posted under the most recent IP). I don’t know him, I have just pinged him because he appears to know Arabic well (ar-4 according to his user page) and he was around at the time and because he surely does not visit the Tea Room else. He does “know” me only because I have constantly watched what is happening with the Arabic pages and thus corrected the layout of his edits; he has learnt well. I don’t know how he is similar other than that he looks how I edit, which is surely justified. See for example the edit history of شمال – do you think that is fake?
- Also, is there anybody else I could ping for Arabic? Tell me. Palaestrator verborum (loquier) 23:20, 28 November 2017 (UTC)
- Thank you for the background. I thought perhaps you knew each other in real life (which is by no means a sin, but your ping could be read as meatpuppetry). As for others to ping for Arabic, look at Category:User ar. —Μετάknowledgediscuss/deeds 00:03, 29 November 2017 (UTC)
- @Metaknowledge: Haha, those are all inactive except Atitarev, me, Profes.I (and Stephen G. Brown whom I do not remember working on Arabic since I have registered and who apparently does not want to partake in receiving what I propose). I take this as no, there isn’t anyone. I don’t know what the Arabs are doing all day, but basically this is all I can do: Ask for confirmation by Profes.I and/or Atitarev lest anybody charge me with acting without consensus, what people here too easily do, or do it myself, as there is the principle of being bold. But in this case I preempted possible later arguments by stating in the Tea Room how the peoples’ names should be dealt with, because I could.
- You really should not imagine meat puppets from my side, I don’t have any friends. It’s harsh in Germany. Palaestrator verborum (loquier) 02:30, 29 November 2017 (UTC)
- Wikitiki89, Kolmiel, and native speaker Mahmudmasri are not inactive, and those are just from memory. Your decision to post a thread first was correct, and any pings are better than no pings, but know that there are more people interested in Arabic than just you. As for friends, I have a few in Germany and I find them quite pleasant people — I'm sure you can find some as well. —Μετάknowledgediscuss/deeds 03:56, 29 November 2017 (UTC)
- @Metaknowledge Your memory errs. Kolmiel has last edited on 31 July 2017, that’s even further away than Benwing. Mahmudmasri has edited five times from the time I have registered, i. e. on his visit it cannot be counted, though it be desirable. Wikitiki89 does deal little with Arabic the last months and hasn’t answered on other occasions. Not inactive enough?
- Another topic: Shouldn’t the babel template decategorize permablocked users? I mean, these user language categories would be more useful without blocked users, if they can’t sort after activity, right? Or if it is technically impossible, there should be a
{{babel-blocked}}that looks the same but does not categorize. Palaestrator verborum (loquier) 00:57, 30 November 2017 (UTC)- I am surprised about Kolmiel. Mahmud and Wikitiki generally respond when pinged, I find. But yes, after some years of editing I will admit that it becomes hard to remember who is active right now and who was active in the recent past. As for the other topic, permabanned users' user pages can be deleted. —Μετάknowledgediscuss/deeds 02:27, 30 November 2017 (UTC)
- @Palaestrator verborum: Are you aware of this vote? His proponent has been inactive ever since, unfortunately, so there hasn't been any follow-through despite the favourable result. --Barytonesis (talk) 13:16, 8 December 2017 (UTC)
- @Barytonesis: I haven’t been aware of the vote. But I have meanwhile found out that the “About X language” pages are used to denote the active users, as for example on Wiktionary:About Persian. It seems easier than the botting. Palaestrator verborum (loquier) 14:05, 8 December 2017 (UTC)
- @Palaestrator verborum: Are you aware of this vote? His proponent has been inactive ever since, unfortunately, so there hasn't been any follow-through despite the favourable result. --Barytonesis (talk) 13:16, 8 December 2017 (UTC)
- I am surprised about Kolmiel. Mahmud and Wikitiki generally respond when pinged, I find. But yes, after some years of editing I will admit that it becomes hard to remember who is active right now and who was active in the recent past. As for the other topic, permabanned users' user pages can be deleted. —Μετάknowledgediscuss/deeds 02:27, 30 November 2017 (UTC)
- Wikitiki89, Kolmiel, and native speaker Mahmudmasri are not inactive, and those are just from memory. Your decision to post a thread first was correct, and any pings are better than no pings, but know that there are more people interested in Arabic than just you. As for friends, I have a few in Germany and I find them quite pleasant people — I'm sure you can find some as well. —Μετάknowledgediscuss/deeds 03:56, 29 November 2017 (UTC)
- Thank you for the background. I thought perhaps you knew each other in real life (which is by no means a sin, but your ping could be read as meatpuppetry). As for others to ping for Arabic, look at Category:User ar. —Μετάknowledgediscuss/deeds 00:03, 29 November 2017 (UTC)
Welcome and a note
[edit]Hi Profes.I. I just wanted to leave a note about the use of context labels like {{label|ar|zoology}}. This is only intended for terms that are only used in the context of zoology. Names of animals that are regularly used aren't just zoological terms, so they don't need a context label — they just need to be categorised at the bottom of the entry.
Additionally, I see that I neglected to give you the welcome message, so here you are! Be sure to ask if you need anything.
Welcome!
Hello, welcome to Wiktionary, and thank you for your contributions so far.
If you are unfamiliar with wiki editing, take a look at Help:How to edit a page. It is a concise list of technical guidelines to the wiki format we use here: how to, for example, make text boldfaced or create hyperlinks. Feel free to practice in the sandbox. If you would like a slower introduction we have a short tutorial.
These links may help you familiarize yourself with Wiktionary:
- Entry layout (EL) is a detailed policy documenting how Wiktionary pages should be formatted. All entries should conform to this standard. The easiest way to start off is to copy the contents of an existing page for a similar word, and then adapt it to fit the entry you are creating.
- Our Criteria for inclusion (CFI) define exactly which words can be added to Wiktionary, though it may be a bit technical and longwinded. The most important part is that Wiktionary only accepts words that have been in somewhat widespread use over the course of at least a year, and citations that demonstrate usage can be asked for when there is doubt.
- If you already have some experience with editing our sister project Wikipedia, then you may find our guide for Wikipedia users useful.
- The FAQ aims to answer most of your remaining questions, and there are several help pages that you can browse for more information.
- A glossary of our technical jargon, and some hints for dealing with the more common communication issues.
- If you have anything to ask about or suggest, we have several discussion rooms. Feel free to ask any other editors in person if you have any problems or question, by posting a message on their talk page.
You are encouraged to add a BabelBox to your userpage. This shows which languages you know, so other editors know which languages you'll be working on, and what they can ask you for help with.
I hope you enjoy editing here and being a Wiktionarian! If you have any questions, bring them to the Wiktionary:Information desk, or ask me on my talk page. If you do so, please sign your posts with four tildes: ~~~~ which automatically produces your username and the current date and time.
Again, welcome! —Μετάknowledgediscuss/deeds 03:00, 5 December 2017 (UTC)
Two things:
- You have added جَمَل اليَهُود (jamal al-yahūd) to حِرْبَاء (ḥirbāʔ). The same day I have removed that definition from جَمَل (jamal) because it looks like it means mantis. It is easy to imagine how there could have appeared a myth about it meaning chamaleon in dictionaries: Somebody read about جَمَل اليَهُود (jamal al-yahūd) being able to hide and having some other characteristics and his first thought has been “chameleon” though “mantis” fits too.
- I have made a template for Georg Freytag’s Lexicon arabico-latinum. Always use the volume and page number so it links the page:
{{R:ar:Freytag|page=34|volume=1}}. With the first positional parameter the entry name can be overwritten. Palaestrator verborum (loquier) 22:00, 5 December 2017 (UTC)- When I was a much younger man I was taught the Jewish Camel was a Chameleon with the explanation of being named for the high arched back of the creature such as in the local Veiled Chameleon; the appellation Jewish is really more like Judean, being prominent in the regions of Palestine. I have heard the mantis being referred to the same, but this is perhaps correlated from its other Arabic name of being Solomon's Horse; one of the Hebrew names for Chameleon is גְּמַל שְׁלֹמֹה, the camel of Solomon. This typically is derived from a folk tale about Solomon using his sorcery on a stubborn camel of his, transforming it to the insect. I don't think there is a right or wrong answer as Arabs likely utilize both depending on the person, region, and context; it should probably be listed with both significances if we want to be comprehensive.
- Additionally, I noticed the Greek etymology χαμαιλέων and its descendants do not mention that it is a calque from the Akkadian nēš qaqqari literally Lion of the Ground.
- Thank you for the Freytag template, I'm sure it will be useful down the road; and thank you in general for your input, it has made me a more valuable contributor to Wiktionary. Profes.I. (talk) 00:58, 6 December 2017 (UTC)
- When I was a much younger man I was taught the Jewish Camel was a Chameleon with the explanation of being named for the high arched back of the creature such as in the local Veiled Chameleon; the appellation Jewish is really more like Judean, being prominent in the regions of Palestine. I have heard the mantis being referred to the same, but this is perhaps correlated from its other Arabic name of being Solomon's Horse; one of the Hebrew names for Chameleon is גְּמַל שְׁלֹמֹה, the camel of Solomon. This typically is derived from a folk tale about Solomon using his sorcery on a stubborn camel of his, transforming it to the insect. I don't think there is a right or wrong answer as Arabs likely utilize both depending on the person, region, and context; it should probably be listed with both significances if we want to be comprehensive.
Some rarer templates I know
[edit]I have found just about {{examples-right}} by seeing it in bahuvrihi – it is virtually unused if you look at the pages linking to the template. I think that this is also usable for collocations that won’t get own entries. On this occasion I write you this, and also mention {{+obj}}. {{+obj}} has come in handy in اشتق, the only Arabic entry using it right now (theoretically it should be {{+preo}}, but there are problems with at is as shewn on Talk:اشتق. Then I have recently found out about {{short for}} and {{clipping of}} (the latter unlikely to be useful in Arabic). Palaestrator verborum (loquier) 18:10, 7 December 2017 (UTC)
Made a template for the Dictionary of the Ugaritic Language
[edit]It works like the Lane template: {{R:uga:DUL-3}}. On this occasion, maybe you can find use for the book {{R:sem-pro:FS Militarev}} which is made to print author and essay names just by the page numbers. Maybe you should take a glimpse into Category:Arabic reference templates too, there is some unused stuff. Palaestrator verborum sis loquier 🗣 18:19, 4 January 2018 (UTC)
This is a useful template, which works just like the etymological templates but avoids categorising an entry as deriving from, say, Tamil, when you simply want to show that a Tamil term is or may be related. See my change here for an example. —Μετάknowledgediscuss/deeds 06:48, 7 July 2018 (UTC)
Some lexemes the etymologies of which you can perhaps lead further
[edit]In case you ask yourself about unlisted incomplete etymologies, I list some here with reverence: حِلْتِيت (ḥiltīt) / حِلْتِيث (ḥiltīṯ, “asafoetida”), إِذْخِر (ʔiḏḵir, “citronella”), بَامِيَة (bāmiya, “okra”), جُمَّيْز (jummayz, “sycomore”), قَرْع (qarʕ, “pumpkin”), لَبْلَاب (lablāb, “ivy”), عَقِيق (ʕaqīq, “agate, carnelian”), سِوَار (siwār, “bracelet”), قَلَنْسُوَة (qalansuwa, “coif”), أَصِيص (ʔaṣīṣ, “pot”), سِكِّين (sikkīn, “knife”). Also, people got icky about بُرْج (burj). Fay Freak (talk) 10:53, 24 July 2018 (UTC)
How you can see hidden categories under every entry
[edit]In your Preferences in the Tab Appearance there is a checkbox Show hidden categories whereby you will see categories like Category:Akkadian terms needing native script. Also in Special:Search you can filter by namespaces to find things, either by checkboxes or by prefixing Category: etc. in the search box. Fay Freak (talk) 20:47, 14 August 2018 (UTC)
Formatting Middle Persian links
[edit]Hi, Middle Persian links should be formatted as: Middle Persian 𐫀𐫡𐫉𐫏𐫉 (ʾrzyz), [Book Pahlavi needed] (ʾlcyc /arzīz/). Thanks. --{{victar|talk}} 05:47, 9 March 2019 (UTC)
رضا
[edit]If you're able to do so, could you check the example sentence that I gave to the Arabic entry رضا?
In other news, you may recite the phrases 法輪大法好,真善忍好 (Fǎlún Dàfǎ hǎo, zhēn shàn rěn hǎo - Falun Dafa is good; Truthfulness, Compassion, Forbearance is good), if you wish. --Lo Ximiendo (talk) 07:36, 3 April 2019 (UTC)
- P.S. I got the idea for the example sentence from an article of the Bitter Winter magazine, which has good articles on Communist repression. --Lo Ximiendo (talk) 12:32, 3 April 2019 (UTC)
حناء
[edit]Can you please provide sources for your etymology on Arabic حناء (ḥinnāʾ, “henna”)? I'm otherwise inclined to discard it. --{{victar|talk}} 20:50, 11 April 2019 (UTC)
Community Insights Survey
[edit]Share your experience in this survey
Hi Profes.I.,
The Wikimedia Foundation is asking for your feedback in a survey about your experience with Wiktionary and Wikimedia. The purpose of this survey is to learn how well the Foundation is supporting your work on wiki and how we can change or improve things in the future. The opinions you share will directly affect the current and future work of the Wikimedia Foundation.
Please take 15 to 25 minutes to give your feedback through this survey. It is available in various languages.
This survey is hosted by a third-party and governed by this privacy statement (in English).
Find more information about this project. Email us if you have any questions, or if you don't want to receive future messages about taking this survey.
Sincerely,
RMaung (WMF) 14:34, 9 September 2019 (UTC)
Reminder: Community Insights Survey
[edit]Share your experience in this survey
Hi Profes.I.,
A couple of weeks ago, we invited you to take the Community Insights Survey. It is the Wikimedia Foundation’s annual survey of our global communities. We want to learn how well we support your work on wiki. We are 10% towards our goal for participation. If you have not already taken the survey, you can help us reach our goal! Your voice matters to us.
Please take 15 to 25 minutes to give your feedback through this survey. It is available in various languages.
This survey is hosted by a third-party and governed by this privacy statement (in English).
Find more information about this project. Email us if you have any questions, or if you don't want to receive future messages about taking this survey.
Sincerely,
RMaung (WMF) 19:14, 20 September 2019 (UTC)
Advice?
[edit]Pranams, I see you are a professional linguist and been using Wiki for a couple years. I am in no way linguistically adept, but my siksha guru is. I have been trying to find ways to get his important research onto Wiki, but it has been difficult since publishers have no interest in his work. I bet if you look at it you will appreciate it, and might knows ways I can get his insights onto Wiki. He shows how deity names and religious terms from various cultures are cognate. I will give you his website, but also one article from there that gives many of his linguistic correlations so you do not have to spend too much time looking through all the articles. If you are on Facebook he has much more info here, on his Saint Francis of Assisi Ecumenical Retreat page and in groups and on certain people’s pages. https://bhaktianandascollectedworks.wordpress.com/2010/11/07/radha-krishna-and-samkarshana-at-the-heart-of-world-monotheism/ https://bhaktianandascollectedworks.wordpress.com/direct-links-to-all-articles-on-the-site/
THNAKS DErnestWachter (talk) 16:48, 3 October 2019 (UTC)
Reminder: Community Insights Survey
[edit]Share your experience in this survey
Hi Profes.I.,
There are only a few weeks left to take the Community Insights Survey! We are 30% towards our goal for participation. If you have not already taken the survey, you can help us reach our goal! With this poll, the Wikimedia Foundation gathers feedback on how well we support your work on wiki. It only takes 15-25 minutes to complete, and it has a direct impact on the support we provide.
Please take 15 to 25 minutes to give your feedback through this survey. It is available in various languages.
This survey is hosted by a third-party and governed by this privacy statement (in English).
Find more information about this project. Email us if you have any questions, or if you don't want to receive future messages about taking this survey.
Sincerely,
RMaung (WMF) 17:04, 4 October 2019 (UTC)
Cuneiform spellings
[edit]Hi, professor. I would like to create some Urartian entries, but I am not familiar with cuneiform. If I know the precise transliteration, e.g. dši-i-ú-i-ni ‘the Urartian Sun God’, is there an easy way to convert it to Unicode cuneiform? --Vahag (talk) 19:37, 10 April 2020 (UTC)
- I have actually considered writing a guide to cuneiform for Wiktionary to help enable others, but creating such a page would be a first for me, my unfamiliarity. If you have a precise transliteration it is for the most part a much easier feat with some modern tools; in the past you would have to find or compile your own charts.
- Steve Tinney of University of Pennsylvania developed Cuneify, which has a few online iterations such as the one linked. It has the vast majority of signs, especially the normal determinatives and core syllable signs.
- It also allows for not having to use specialized transliteration symbols; š=sz; ṣ=s,; and ṭ=t,; instead.
- You can use lower-case (for syllables) and/or UPPER-CASE (for logograms); this is not necessary one way or another. Transliteration uses the convention of capitalizing logograms like Sumerian elements, separated by a "." and using lower-case for syllables separated by "-".
- Likewise you can use hypens (-), spaces, or full stops to separate the signs, but not new lines/returns. Cuneify will put spaces between each sign, these must be taken out for the form we are looking to post here; a word has no internal spaces, space indicates a following word as with most scripts.
- For diacritics (subscript numerals) you can type normal numerals, but you can also use accents like your symbol "ú". That is to say u is u, u2 is ú, u3 is ù; 1st form is nothing, 2nd variation is a right accent, 3rd variation is a left accent. Further variations use solely number combos, u4 is u4 and u5 is u5 etc. I personally prefer to use subscripts "2" and "3" when transliterating here at Wiktionary to keep it consistent.
- You can type the divine, female, and male determinatives as d-, f- and m-, or as {d}, {f} and {m} (and the other determinatives too). Transliteration practice is to use super-scripts for these elements.
- Another cool feature, if you type numbers in the decimal system they are converted automatically to base 60.
- Occasionally older sources might list a sign a little differently, or the spelling is utilizing a sign in a not-so-common way and you may have to find a more common name for it or else it will come back with an error.
- In this case using an extended sign-list and manually having to look it up; here is a handy one compiled by Kateřina Šašková, Cuneiform Sign List.
- Search the page, find the sign you are looking for; you can copy it manually or just type the newly found more common name in Cuneify in place of the unknown sign name for the same result.
- If you are having trouble or simply want to move on to adding more entries, you can always leave the cuneiform blank and I will personally go about supplying the script. I do not mind doing so, I check the cuneiform script requests habitually, and especially if there is already a listed transliteration, it is no trouble at all. A good habit for cuneiform users here at Wiktionary is to always supply both transliterations (tr=) and normalized/citation forms (ts=) if one can; it not only allows laymen more access to find what information they were looking for, but also a better way for the information to double checked.
- There is a reason cuneiform died out so quickly after being so long established; its daunting, it can be messy and mistakes exist abundantly, do not be discouraged. Give it a try for yourself; dši-i-ú-i-ni (alternatively d szi i u2 i ni) should give us this: 𒀭𒅆𒄿𒌑𒄿𒉌 (dši-i-u2-i-ni /Šivini, Šiuini, Šiwini/, “the Urartian Sun God”).
- There are some personal variations found in each language that adopted cuneiform, usually progressing towards simplification and utility for their language needs. I do not want to be that guy who complicates things, but often times there will be other spelling conventions for commonly used words; the only way to learn them is being completely immersed in a cuneiform corpus much in the way the original scribes were. An alternative way attested for writing Šiuini in cuneiform is 𒀭𒌓𒉌 (dUTU-ni /Šivini, Šiuini, Šiwini/, “the Urartian Sun God”). It uses to Sumerian Signs "DINGIR - god" and "UTU - sun", followed by -ni; adding phonetic compliments to familiar Sumerograms and Akkadograms is one way to shortcut spellings.
- Of possible interest and of aid to you, this source will help you see if a form is directly attested in our known corpus of Urartian inscriptions; Electronic Corpus of Urartian Texts and Hub Page which gives specific set lists of information; Palaeolexicon also has a Urartian dictionary. Best regards fellow scholar -Profes.I. (talk) 13:41, 11 April 2020 (UTC)
- This guide and these tools are exactly what I have been looking for. Thank you very much! --Vahag (talk) 13:07, 12 April 2020 (UTC)
- You're quite welcome, I hope it serves you well; Urartian is not my strong suit, but has always peeked curiosity when I've come across it. I did make an error in the above, although it is valid that phonetic compliments are often times added to known logograms, this happens to not be one of those cases. The -ni ending is a Urartian grammatical suffix, the proper alternative spelling would be to use 𒀭𒌓 (dUTU /Šivini, Šiuini, Šiwini/, “the Urartian Sun God”) literally meaning Sun God. -Profes.I. (talk) 01:33, 13 April 2020 (UTC)
- This guide and these tools are exactly what I have been looking for. Thank you very much! --Vahag (talk) 13:07, 12 April 2020 (UTC)
Etymology-only languages
[edit]Hi! Just to let you know (in case you don't), our templates recognize various "etymology-only" language codes that could be used in the etymology sections, such as elx-ach for Achaemenid Elamite (list). --Z 13:52, 19 April 2020 (UTC)
Hi. Could you please check this IP's Semitic-related contributions? — surjection ⟨??⟩ 20:54, 22 May 2020 (UTC)
- Special:Contributions/74.90.121.254 is the same problem editor. Could you please check the Elamite? —Μετάknowledgediscuss/deeds 00:45, 11 August 2020 (UTC)
- They actually check out as valid Elamite names attested in the Achaemenid period, the cunieform is accurate as well for the transcription. -Profes.I. (talk) 03:28, 11 August 2020 (UTC)
- That's somewhat unexpected, but good to hear! —Μετάknowledgediscuss/deeds 04:16, 11 August 2020 (UTC)
- They actually check out as valid Elamite names attested in the Achaemenid period, the cunieform is accurate as well for the transcription. -Profes.I. (talk) 03:28, 11 August 2020 (UTC)
- There are multiple discussions about language code wrangling at WT:RFM that could benefit from your thoughts. You can of course skim the table of contents, but WT:RFM#Cleanup suggestions for some badly attested Semitic languages, needing admin action is probably the most interesting to you. —Μετάknowledgediscuss/deeds 06:52, 17 August 2020 (UTC)
We sent you an e-mail
[edit]Hello Profes.I.,
Really sorry for the inconvenience. This is a gentle note to request that you check your email. We sent you a message titled "The Community Insights survey is coming!". If you have questions, email surveys@wikimedia.org.
You can see my explanation here.
MediaWiki message delivery (talk) 18:48, 25 September 2020 (UTC)
Cuneiform help required
[edit]Hello. I was told that I should refer to you should I need help concerning editing with cuneiform, and I was wondering if you could please help me identify the cuneiform signs in this image below? So far I have only been able to identify 𒉺,𒃻, and 𒁺, but I am having trouble identifying the other signs.

There are also a number of Old Persian entries which need script for Akkadian and Elamite cuneiform:
- Reconstruction:Old Persian/Bagapātaʰ
- Reconstruction:Old Persian/Ciçafarnāʰ
- Reconstruction:Old Persian/Farnadātaʰ
- Reconstruction:Old Persian/Miθrapātaʰ
- Reconstruction:Old Persian/Parušyātiš
- Reconstruction:Old Persian/Raucakaʰ
- Reconstruction:Old Persian/R̥tastūnā
- Reconstruction:Old Persian/R̥tavazdāʰ
- Reconstruction:Old Persian/Vaʰumanāʰ
- Reconstruction:Old Persian/Ātr̥dātaʰ
- Reconstruction:Old Persian/Ātr̥pātaʰ
- Reconstruction:Old Persian/Šyātifarnāʰ
- 𐎠𐎼𐎫𐎧𐏁𐏂𐎠
- 𐎣𐎲𐎢𐎪𐎡𐎹
- 𐎧𐏁𐎹𐎠𐎼𐏁𐎠
- 𐎭𐎠𐎼𐎹𐎺𐎢𐏁
- 𐎶𐎼𐎯𐎢𐎴𐎡𐎹
And I'd like to ask your help to fill the missing script gaps for these pages. Antiquistik (talk) 04:36, 10 September 2021 (UTC)
- I am glad to be of some help if I so can; I had the intention to get back to those missing scripts when time better permitted, but of course your help would be greatly appreciated. Life has been extra busy, finished up working on a book, as well as being a keynote speaker, things that often sap my focus. So I do apologize for the delays and hiatuses that have been a little more frequent as of late for myself.
- Good news, most of those are just time consuming, not inherently difficult with the right tools. Above on my talk page under the section Cuneiform Spellings there are some of these tools outlined; in particular: Cuneify, the Cuneiform Sign List, and the Cuneiform Script Analyzer.
- Just for examples sake, the first missing script on Bagapātaʰ requests for: "bag-ʾ-a-pa-a-tu₄". With a transliteration all you have to do is copy this into Cuneify and it generates the Unicode, namely: 𒄷𒀪𒀀𒉺𒀀𒌈 (bag-ʾ-a-pa-a-tu₄), do make sure the spaces between the characters are removed. That's it, simple despite the massive pile up of missing script requests; my advice would be to edit and publish changes in stages rather than all in one edit.
- Now on occasion scribes like to make us jump through hoops, albeit easier for the writer, the emoji-mentality was hard to decipher at times to the degree that different scribal traditions had to transliterate messages from one another (especially when between Neo-Assyrian and Neo-Babylonian); they were as different as another script despite their once common origin. With that being said you will find the joys and horrors of creative spelling :) it's a puzzle of sorts and the more practice at it, the less daunting it seems. I will remind however that within a generation of the alphabet being introduced, the whole system of writing was largely abandoned; everyone was on the same page even back then of its unwieldiness.
- The first symbol in your image request is definitely the hardest one to find, it is likely a scribal variant of 𒉈 (NE). However, it is also likely not part of the word, but a compliment used to help narrow down the following sign. The sign 𒉺 (PA) would normally be presumed to be read "PA", however it could also be: ARI₃, ARU, BA₂, DURU₆, ENDUR, GIDRI, GIDRU, GIŠTURU, ḪAD, ḪAMAN, ḪANIŠ₃, ḪAS₂, ḪAṢ₂, ḪAT, ḪATA, ḪAṬ, ḪAZ₂, ḪENDUR, ḪUD, KUN₂, KUNGA, KUR₁₀, LAR, LU₉, LUG₂, LUN, MAŠ₄, MIDRA, MU₆, MUA, MUATI, MUATU, MUDRA, MUDRU, MUIA, SAG₃, SAK₃, SEG₃, SEGGA₂, SIG₃, SIGGA₂, SULLAT₂, ŠAG₃, ŠAK₃, ŠAQ₃, ŠULLAT₂, UGULA, UGULU, WI₂, ZAG₂, ZAK₂, ZAQ₂. Yeah I think you could infer the problem, and so especially nearing the end of Cuneiform's usage it was more and more common for signs to be used to cut down the ambiguity. Now you might be saying Profes.I none of those start with "N" how does this help me narrow it down; the next problem. The script was designed and layered with obsolete prestige spellings, a great deal of them originating in a language not even of the same language family or any longer in existence. The god Muati is later presumed to be one and the same as the god known by the later name Nabu, one of the most common spelling, if not the most, being: 𒀭𒉺 (DMUATI, “Nabu”), with the superscript D representing the deity determinative.
- So to solve this, we have a scribe who writes "NE.PA" because they mean to say it's not PA, but Muati aka Nabu, they want to say Nabu and that was the not quite straightforward route they took. I checked the rest of the Babylonian Chronology and History by G. Bertin and found this symbol repeated again in the very latest period of Babylonian history before Cyrus shook things up; the last king of the Neo-Babylonian empire Nabonidus. G. Bertin mentions that this list he has created was a collation of 3 very fragmentary tablets in particular, including some smaller ones when needed to fill in gaps; his goal was to try to create the first complete timeline of rulers in the region by chronological succession. As the list is a composite of many tablets, works of many scribes, I would imagine Bertin's transcription for the names Nebuchadnezzar II and Nabonidus were from the same hand or at least the same school of scribes. This accounts for the seeming variation instead of the more commonly found spellings of Nebuchadnezzar II; this scribe wanted to spell it this way and so they did whenever they needed the word Nabu.
- You did quite well to identify the following signs for the "kudurru" part, and the final one is a little harder to see by its transcription, so also understandable. Sometimes it is like that, between the scribes creative freedom, the classical scholar's newly coined conventions and then lastly our modern reinterpreting with new available data; they often clash adding even more names and readings for signs. The symbols ŠEŠ and URU₃ are very similar in appearance and oftentimes in meanings; again a quick peruse down Bertin's list we see the sign used in other names as well, namely ones ending with aḥe and uṣur. For simplicity, the signs mean "brother" and "guard" semantically in Sumerian; the Semitic words, akh and uṣur (from n-ṣ-r in the command form with an assimilated-n) mean the same respectively. What has happened here, again probably because of the collation of tablets, is two different sign developments. In older forms, these symbols are only marginally different, later on the symbols diverged in some schools and not others. So apparently some scribes thought they were interchangeable and confirmation of this can be seen in the "other form" being used equally interchangeably in Bertin's list. We have some akh's that are spelt URU₃ or with ŠEŠ and we have some uṣur's spelt URU₃ or with ŠEŠ; we are not consistent throughout. You can play around a little bit with this on Cuneify using their different available fonts: szesz and uru3 will generate sometimes the same and sometimes different signs depending on the period and region.
- So after the unplanned book I just wrote, what we get is something that can be transcribed: 𒉈𒉺𒃻𒁺𒌶 (NE.MUATI.NIG₂.DU.URU₃ /nabu-kudurri-uṣur/, “Nebuchadnezzar (II)”). Hopefully despite the length, it was helpful to you now and going forward; best regards from a fellow scholar -Profes.I. (talk) 03:11, 11 September 2021 (UTC)
- Thanks for all this help! I appreciate the detailed explanation and the tools. Antiquistik (talk) 04:48, 11 September 2021 (UTC)
- It appears that the tools you linked me to work for Akkadian and Sumerian, but not for Elamite cuneiform. What resources should I use for the missing Elamite script on the entries?
- I also need to identify the signs on this image:
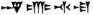 . So far I have identified 𒀸,𒋩, and 𒋾, for certain. But I am not sure if the second sign is 𒂵 and the final sign is 𒆷. Could you confirm if these are accurate, or whether I misidentified them?
. So far I have identified 𒀸,𒋩, and 𒋾, for certain. But I am not sure if the second sign is 𒂵 and the final sign is 𒆷. Could you confirm if these are accurate, or whether I misidentified them? - Also, is there any template on Wiktionary which allows for rendering different forms of cuneiform script according to time period of cuneiform similar to Wikipedia's
{{cuneiform}}? Antiquistik (talk) 08:28, 11 September 2021 (UTC)- The good news, most cuneiform scripts outside of Sumerian and Akkadian developed off of Akkadian. You will find that the trend, and logically, was just to minimize the sign inventory, often by limiting it to phonetic spelling (CV and VC, and much more rarely CVC), not distinguishing sounds (Elamite could not differentiate Ci and Ce from one another so only one sign for both is used in most cases), and lastly to cut the prestige spellings if they could (why bring Sumerian along). Elamite only used about 200 or so signs in its entire lifespan, with about 125ish at one period to another at a time. If you take a look at some of the lemmas for other cuneiform script languages you will see there is no variation, it's all the same Unicode signs we use for Akkadian entries as well. Now on occasion you will find a glyph that Cuneify does not have in its bank, usually because it is not as common or referred to by a more common name. That is where the Sign List comes in to find it manually; scholars studying Elamite did not necessarily call a sign by the same name even if the same sign did indeed exist in Akkadian, so that is where you will find the Unicode by its alternative names.
- Very close on this image as well, it is 𒀸𒋩𒌑𒋾𒆷 (aš-šur-ú-TI.LA, “Aššur-uballiṭ (II)”); the capital letters separated instead by "." represent Sumerian in Akkadian cuneiform transliterations. The root "b-l-ṭ" is a Semitic reading representing the same concept of "sustaining life", however "TI.LA" was already used far longer beforehand to indicate as much. A new/phonetic Semitic spelling was not rendered to replace it; why reinvent the wheel was their thought process. For some reassurance 𒂵 (GA) and 𒌑 (U₂) are very close in appearance in their later stages, the former featuring two so-called "winkelhakens" where we find two so-called "ashs" in the later, but otherwise identical.
- As for the last inquiry I unfortunately often find myself as antiquated and cumbersome as a cuneiform tablet when it comes to the specifics of coding. I know the Unicode blocks are the same, so when you see a different font, that is all it is, different renderings of the same Unicode points, not new separate signs of their own. So what we get is a replacement, not an addition to; I do believe there must be some way to indicate what font in HTML, for instance take a look at the Sign List, we have two sets of Cuneiform Unicode one column apart, but different fonts. That is another thing, if you do not have the font downloaded and placed in your fonts location, the script will not render or only render with the one available for those Unicode points. I am not sure exactly what gives one font precedence over another, is it the last font added, selected program specific, etc. but only one will be active at a time. With that being said, no I do not believe, and most importantly here at Wiktionary, there is a means to distinguish the different time periods and regions specifically. This is a blessing and curse, as its harder sometimes to identify which signs to use by appearance on actual clay, as you are seeing already, but also allows for it to be more easily recognized once here, as they are consistent visually every time you see one of the lemmas no matter what period. In due time you'll begin to recognize signs, especially commonly used ones like determinatives and the core phonetic syllabary.
- Again hopefully the best in your endeavor and it is greatly appreciated your interest in helping our community this way. -Profes.I. (talk) 10:37, 11 September 2021 (UTC)
- Thanks for all this help! I appreciate the detailed explanation and the tools. Antiquistik (talk) 04:48, 11 September 2021 (UTC)
- Thanks yet again, especially for the kind words. If I may ask for help with another set of images, could you please confirm which one between 𒎙 at once or two 𒌋's which denotes Šamaš in
 , which sign is used to write līšir in
, which sign is used to write līšir in 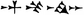 , and which sign along with 𒋢 is used for erība in
, and which sign along with 𒋢 is used for erība in  ? Antiquistik (talk) 13:14, 11 September 2021 (UTC)
? Antiquistik (talk) 13:14, 11 September 2021 (UTC)
- In the first instance either is acceptable; in the minds of the ancients they were two angular-hooks, not one Unicode symbol. I believe for instance if you added 𒎙 to the Cuneiform Script Analyzer it will process them separately even though the Unicode was originally one point. We refer to them as a Winkelhaken, two Winkelhakens, three Winkelhakens and so forth, because in reality that is what they are; it is not 20 but really 10+10, not 30 but 10+10+10. So we have something like this: 𒎙𒈬𒁺 (UTU.šum₃-kin₇, “Šamaš-šum-ukin”).
- In instance two, we see a similar problem as the very first one asked, where a scribe has taken liberties to create a variant sign, albeit with some logical substitutions based on other similar sign developments. The sign is actually 𒋓 (šir), a clipping of the word "išir", "to be prosperous". Good evidence of this can be seen firstly in the rendering of signs like 𒄭 (ḫi) into the same pattern we see in the center of our sign here. The second verification for the coining is the progression of 𒋓 (šir), which later featured an ash-symbol in its center and another to its right, in the fashion of 𒐀 (2). In other words, we have a 𒋓 (šir) altered by collapsing its "circle" and maintaining the two to the right of its medial form, instead of the one to the right that we see in older forms. So we have something like this: 𒀭𒈬𒋓 (Dšum₃-šir, “Sīn-šumu-līšir”)
- In the last case we have the common symbol 𒈨𒌍 (“MEŠ”) used to pluralize animate things; 𒉽𒈨𒌍 (aḫa.MEŠ, “brothers”). So we have something like this: 𒀭𒌍𒉽𒈨𒌍𒋢 (D30-aḫa.MEŠ.SU, “Sīn-aḫḫū-erība; Sīn has entered in a new one of the brothers”), theorized to mean that he was either born or adopted this name after all his elder brothers, the heirs apparent, had become deceased, as he was known not to be Sargon II's eldest son. -Profes.I. (talk) 22:53, 12 September 2021 (UTC)
- Thank you yet again! Your help was deeply appreciated! Antiquistik (talk) 02:25, 13 September 2021 (UTC)
- Thanks yet again, especially for the kind words. If I may ask for help with another set of images, could you please confirm which one between 𒎙 at once or two 𒌋's which denotes Šamaš in
Hi, I'm sorry to bother you again but I'd like to request checking over the Philistine entries 𐤈𐤓𐤍, 𐤏𐤒𐤓𐤍, 𐤀𐤊𐤉𐤔 that were created by a now blocked editor. — surjection ⟨??⟩ 20:01, 4 October 2021 (UTC)
- Good news, like the previously requested check, these all appear to be in good shape. Additionally, no worries, feel free to ask anytime, better safe than sorry; it's a group effort and I am glad I can help contribute. -Profes.I. (talk) 13:03, 5 October 2021 (UTC)
Elamite sign help
[edit]Could you please identify which Elamite cuneiform sign is transcribed as h in the entries h.šu-šá, h.šu-šá-an, and h.šu-še-en of the Elamisches Wörterbuch? Antiquistik (talk) 18:00, 21 September 2022 (UTC)
- The joys of transliterations and transcriptions :) I imagine it is probably short for something like Haus or Heim, indicating a place determinative. I think perhaps being that it is not capitalized or even super-scripted would imply, despite being a determinative, it is an innovation rather than an inherited "Sumerogram/Akkadogram", a pseudo one that Elamite scribes coined themselves. In the Behistun inscription they use diš for individuals and aš for places which is not its typical use. The sign aš is however used as a logogram for ina (“in, on, at”), a particle commonly used in conjunction with places, which might be the source for this application. -Profes.I. (talk) 23:50, 21 September 2022 (UTC)
- Thanks for the help! Antiquistik (talk) 07:09, 22 September 2022 (UTC)
Hi, I noticed you added the etymology to مرج#Etymology_4. What's your source for the Akkadian term? I can't find it in any of my books. Thanks. --{{victar|talk}} 05:48, 6 November 2023 (UTC)
- OK, I found a couple of terms in
{{R:akk:CAD|page=278f|part=1|volume=10}}: [Term?] (/marġû/, “topographic term”) and [Term?] (/marġūlu/, “field”), but it doesn't give the cuneiform. --{{victar|talk}}06:14, 6 November 2023 (UTC)- Probably a mistake on my part, so thank you for finding; just solely based off its transcription, it should be spelt as 𒈥𒄖𒌋 (mar-gu-u /margû/). This is the same spelling given to its homophone marġû A: 𒈥𒄖𒌋 (mar-gu-u /margû/, “bear”) right above it, which is why it does not appear again unnecessarily in CAD; the spellings are identical. For your future reference or anyone else who comes upon this, the convention in standard format Akkadian transliteration, the circumflex indicates a long vowel resulting from a contraction; "â" just means 𒀀 (__a-a), "ê" 𒂊 (__e-e), "î" 𒄿 (__i-i), "û" 𒌋 (__u-u), following a sign that ends in a/e/i/u respectively. -Profes.I. (talk) 07:45, 6 November 2023 (UTC)
- Much obliged. --
{{victar|talk}}08:48, 6 November 2023 (UTC)
- Much obliged. --
- Probably a mistake on my part, so thank you for finding; just solely based off its transcription, it should be spelt as 𒈥𒄖𒌋 (mar-gu-u /margû/). This is the same spelling given to its homophone marġû A: 𒈥𒄖𒌋 (mar-gu-u /margû/, “bear”) right above it, which is why it does not appear again unnecessarily in CAD; the spellings are identical. For your future reference or anyone else who comes upon this, the convention in standard format Akkadian transliteration, the circumflex indicates a long vowel resulting from a contraction; "â" just means 𒀀 (__a-a), "ê" 𒂊 (__e-e), "î" 𒄿 (__i-i), "û" 𒌋 (__u-u), following a sign that ends in a/e/i/u respectively. -Profes.I. (talk) 07:45, 6 November 2023 (UTC)